Значимость уравнения регрессии в целом оценивает. Решение средствами табличного процессора Excel
Для оценки существенности, значимости коэффициента корреляции используется t-критерий Стьюдента.
Находится средняя ошибка коэффициента корреляции по формуле:
Н а
основе ошибки рассчитываетсяt-критерий:
а
основе ошибки рассчитываетсяt-критерий:
Рассчитанное значение t-критерия сравнивают с табличным, найденным в таблице распределения Стьюдента при уровне значимости 0,05 или 0,01 и числе степеней свободы n-1. Если расчетное значение t-критерия больше табличного, то коэффициент корреляции признается значимым.
При криволинейной связи для оценки значимости корреляционного отношения и уравнения регрессии применяется F-критерий. Он вычисляется по формуле:

или

где η – корреляционное отношение; n – число наблюдений; m – число параметров в уравнении регрессии.
Рассчитанное значение F сравнивается с табличным для принятого уровня значимости α (0,05 или 0,01) и чисел степеней свободы к 1 =m-1 и k 2 =n-m. Если расчетное значение F превышает табличное, связь признается существенной.
Значимость коэффициента регрессии устанавливается с помощью t-критерия Стьюдента, который вычисляется по формуле:

где σ 2 а i - дисперсия коэффициента регрессии.
Она вычисляется по формуле:

где к – число факторных признаков в уравнении регрессии.
Коэффициент регрессии признается значимым, если t a 1 ≥t кр. t кр отыскивается в таблице критических точек распределения Стьюдента при принятом уровне значимости и числе степеней свободы k=n-1.
4.3.Корреляционно-регрессионный анализ в Excel
Проведём корреляционно-регрессионный анализ взаимосвязи урожайности и затрат труда на 1 ц зерна. Для этого открываем лист Excel, в ячейки А1:А30 вводим значения факторного признака – урожайности зерновых культур, в ячейки В1:В30 значения результативного признака – затраттруда на 1 ц зерна. В меню Сервис выберем опцию Анализ данных. Щелкнув левой кнопкой мыши по этому пункту, откроем инструмент Регрессия. Щелкаем по кнопке OK, на экране появляется диалоговое окно Регрессия. В поле Входной интервал У вводим значения результативного признака (выделяя ячейки В1:В30), в поле Входной интервал Х вводим значения факторного признака (выделяя ячейки А1:А30). Отмечаем уровень вероятности 95%, выбираем Новый рабочий лист. Щелкаем по кнопке OK. На рабочем листе появляется таблица «ВЫВОД ИТОГОВ», в которой даны результаты вычисления параметров уравнения регрессии, коэффициента корреляции и другие показатели, позволяющие определить значимость коэффициента корреляции и параметров уравнения регрессии.
|
ВЫВОД ИТОГОВ | ||||||||
|
Регрессионная статистика | ||||||||
|
Множественный R | ||||||||
|
R-квадрат | ||||||||
|
Нормированный R-квадрат | ||||||||
|
Стандартная ошибка | ||||||||
|
Наблюдения | ||||||||
|
Дисперсионный анализ | ||||||||
|
Значимость F | ||||||||
|
Регрессия | ||||||||
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-Значение |
Нижние 95% |
Верхние 95% |
Нижние 95,0% |
Верхние 95,0% |
|
|
Y-пересечение | ||||||||
|
Переменная X 1 | ||||||||
В данной таблице «Множественный R» - это коэффициент корреляции, «R-квадрат» - коэффициент детерминации. «Коэффициенты: Y-пересечение» - свободный член уравнения регрессии 2,836242; «Переменная Х1» – коэффициент регрессии -0,06654. Здесь имеются также значения F-критерия Фишера 74,9876, t-критерия Стьюдента 14,18042, «Стандартная ошибка 0,112121», которые необходимы для оценки значимости коэффициента корреляции, параметров уравнения регрессии и всего уравнения.
На основе данных таблицы построим уравнение регрессии: у х =2,836-0,067х. Коэффициент регрессии а 1 =-0,067 означает, что с повышением урожайности зерновых на 1 ц/га затраты труда на 1 ц зерна уменьшаются на 0,067 чел.-ч.
Коэффициент корреляции r=0,85>0,7, следовательно, связь между изучаемыми признаками в данной совокупности тесная. Коэффициент детерминации r 2 =0,73 показывает, что 73% вариации результативного признака (затрат труда на 1 ц зерна) вызвано действием факторного признака (урожайности зерновых).
В таблице критических точек распределения Фишера - Снедекора найдём критическое значение F-критерия при уровне значимости 0,05 и числе степеней свободы к 1 =m-1=2-1=1 и k 2 =n-m=30-2=28, оно равно 4,21. Так как рассчитанное значение критерия больше табличного (F=74.9896>4,21), то уравнение регрессии признаётся значимым.
Для оценки значимости коэффициента корреляции рассчитаем t-критерий Стьюдента:
В таблице критических точек распределения
Стьюдента найдём критическое значениеt-критерия
при уровне значимости 0,05 и числе степеней
свободы n-1=30-1=29,
оно равно 2,0452. Так как расчётное значение
больше табличного, то коэффициент
корреляции является значимым.
таблице критических точек распределения
Стьюдента найдём критическое значениеt-критерия
при уровне значимости 0,05 и числе степеней
свободы n-1=30-1=29,
оно равно 2,0452. Так как расчётное значение
больше табличного, то коэффициент
корреляции является значимым.
Для коэффициентов регрессионного уравнения проверка их уровня значимости осуществляется по t -критерию Стьюдента и по критерию F Фишера. Ниже мы рассмотрим оценку достоверности показателей регрессии только для линейных уравнений (12.1) и (12.2).
Y=a 0 + a 1 X (12.1)
Х= b 0 + b 1 Y (12.2)
Для это типа уравнений оценивают по t -критерию Стьюдента только величины коэффициентов а 1и b 1с использованием вычисления величины Тф по следующим формулам:
Где r yx коэффициент корреляции, а величину а 1можно вычислить по формулам 12.5 или 12.7.
Формула (12.27) используется для вычисления величины Тф, а 1уравнения регрессии Y по X.

Величину b 1можно вычислить по формулам (12.6) или (12.8).
Формула (12.29) используется для вычисления величины Тф, которая позволяет оценить уровень значимости коэффициента b 1уравнения регрессии X по Y
Пример. Оценим уровень значимости коэффициентов регрессии а 1и b 1уравнений (12.17), и (12.18), полученных при решении задачи 12.1. Воспользуемся для этого формулами (12.27), (12.28), (12.29) и (12.30).
Напомним вид полученных уравнений регрессии:
Y х = 3 + 0,06 X (12.17)
X y = 9+ 1 Y (12.19)
Величина а 1в уравнении (12.17) равна 0,06. Поэтому для расчета по формуле (12.27) нужно подсчитать величину Sb y х. Согласно условию задачи величина п = 8. Коэффициент корреляции также уже был подсчитан нами по формуле 12.9: r xy = √ 0,06 0,997 = 0,244 .
Осталось вычислить величины Σ (у ι - y ) 2 и Σ (х ι –x ) 2 , которые у нас не подсчитаны. Лучше всего эти расчеты проделать в таблице 12.2:
Таблица 12.2
| № испытуемых п/п | х ι | у i | х ι –x | (х ι –x ) 2 | у ι - y | (у ι - y ) 2 |
| -4,75 | 22,56 | - 1,75 | 3,06 | |||
| -4,75 | 22,56 | -0,75 | 0,56 | |||
| -2,75 | 7,56 | 0,25 | 0,06 | |||
| -2,75 | 7,56 | 1,25 | 15,62 | |||
| 1,25 | 1,56 | 1,25 | 15,62 | |||
| 3,25 | 10,56 | 0,25 | 0,06 | |||
| 5,25 | 27,56 | -0,75 | 0,56 | |||
| 5,25 | 27,56 | 0,25 | 0,06 | |||
| Суммы | 127,48 | 35,6 | ||||
| Средние | 12,75 | 3,75 |
Подставляем полученные значения в формулу (12.28), получаем:
Теперь рассчитаем величину Тф по формуле (12.27):

Величина Тф проверяется на уровень значимости по таблице 16 Приложения 1 для t- критерия Стьюдента. Число степеней свободы в этом случае будет равно 8-2 = 6, поэтому критические значения равны соответственно для Р ≤ 0,05 t кр = 2,45 и для Р≤ 0,01 t кр =3,71. В принятой форме записи это выглядит так:

Строим «ось значимости»:

Полученная величина Тф Н о о том, что величина коэффициента регрессии уравнения (12.17) неотличима от нуля. Иными словами, полученное уравнение регрессии неадекватно исходным экспериментальным данным.
Рассчитаем теперь уровень значимости коэффициента b 1. Для этого необходимо вычислить величину Sb xy по формуле (12.30), для которой уже расчитаны все необходимые величины:
Теперь рассчитаем величину Тф по формуле (12.27):

Мы можем сразу построить «ось значимости», поскольку все предварительные операции были проделаны выше:

Полученная величина Тф попала в зону незначимости, следовательно мы должны принять гипотезу H о о том, что величина коэффициента регрессии уравнения (12.19) неотличима от нуля. Иными словами, полученное уравнение регрессии неадекватно исходным экспериментальным данным.
Нелинейная регрессия
Полученный в предыдущем разделе результат несколько обескураживает: мы получили, что оба уравнения регрессии (12.15) и (12.17) неадекватны экспериментальным данным. Последнее произошло потому, что оба эти уравнения характеризуют линейную связь между признаками, а мы в разделе 11.9 показали, что между переменными X и Y имеется значимая криволинейная зависимость. Иными словами, между переменными Х и Y в этой задаче необходимо искать не линейные, а криволинейные связи. Проделаем это с использованием пакета «Стадия 6.0» (разработка А.П. Кулаичева, регистрационный номер 1205).
Задача 12.2 . Психолог хочет подобрать регрессионную модель, адекватную экспериментальным данным, полученным в задаче 11.9.
Решение. Эта задача решается простым перебором моделей криволинейной регрессии предлагаемых в статистическом пакете Стадия. Пакет организован таким образом, что в электронную таблицу, которая является исходной для дальнейшей работы, заносятся экспериментальные данные в виде первого столбца для переменной X и второго столбца для переменной Y. Затем в основном меню выбирается раздел Статистики, в нем подраздел - регрессионный анализ, в этом подразделе вновь подраздел - криволинейная регрессия. В последнем меню даны формулы (модели) различных видов криволинейной регрессии, согласно которым можно вычислять соответствующие регрессионные коэффициенты и сразу же проверять их на значимость. Ниже рассмотрим только несколько примеров работы с готовыми моделями (формулами) криволинейной регрессии.
1. Первая модель - экспонента . Ее формула такова:
![]()
При расчете с помощью статпакета получаем а 0 = 1 и а 1 = 0,022.
Расчет уровня значимости для а, дал величину Р = 0,535. Очевидно, что полученная величина незначима. Следовательно, данная регрессионная модель неадекватна экспериментальным данным.
2. Вторая модель - степенная . Ее формула такова:
![]()
При подсчете а о = - 5,29, а, = 7,02 и а 1 = 0,0987.
Уровень значимости для а 1 - Р = 7,02 и для а 2 - Р = 0,991. Очевидно, что ни один из коэффициентов не значим.
3. Третья модель - полином . Ее формула такова:
Y = а 0 + а 1 X + а 2 X 2 + а 3 X 3
При подсчете а 0 = - 29,8, а 1 = 7,28, а 2 = - 0,488 и а 3 = 0,0103. Уровень значимости для а, - Р = 0,143, для а 2 - Р = 0,2 и для а, - Р= 0,272
Вывод - данная модель неадекватна экспериментальным данным.
4. Четвертая модель - парабола .
Ее формула такова: Y= a o + a l -X 1 + а 2 Х 2
При подсчете а 0 = - 9,88, а, = 2,24 и а 1 = - 0,0839 Уровень значимости для а 1 - Р = 0,0186, для а 2 - Р = 0,0201. Оба регрессионных коэффициента оказались значимыми. Следовательно, задача решена - мы выявили форму криволинейной зависимости между успешностью решения третьего субтеста Векслера и уровнем знаний по алгебре - это зависимость параболического вида. Этот результат подтверждает вывод, полученный при решении задачи 11.9 о наличии криволинейной зависимости между переменными. Подчеркнем, что именно с помощью криволинейной регрессии был получен точный вид зависимости между изучаемыми переменными.
Глава 13 ФАКТОРНЫЙ АНАЛИЗ
Основные понятия факторного анализа
Факторный анализ - статистический метод, который используется при обработке больших массивов экспериментальных данных. Задачами факторного анализа являются: сокращение числа переменных (редукция данных) и определение структуры взаимосвязей между переменными, т.е. классификация переменных, поэтому факторный анализ используется как метод сокращения данных или как метод структурной классификации.
Важное отличие факторного анализа от всех описанных выше методов заключается в том, что его нельзя применять для обработки первичных, или, как говорят, «сырых», экспериментальных данных, т.е. полученных непосредственно при обследовании испытуемых. Материалом для факторного анализа служат корреляционные связи, а точнее - коэффициенты корреляции Пирсона, которые вычисляются между переменными (т.е. психологическими признаками), включенными в обследование. Иными словами, факторному анализу подвергают корреляционные матрицы, или, как их иначе называют, матрицы интеркорреляций. Наименования столбцов и строк в этих матрицах одинаковы, так как они представляют собой перечень переменных, включенных в анализ. По этой причине матрицы интеркорреляций всегда квадратные, т.е. число строк в них равно числу столбцов, и симметричные, т.е. на симметричных местах относительно главной диагонали стоят одни и те же коэффициенты корреляции.
Необходимо подчеркнуть, что исходная таблица данных, из которой получается корреляционная матрица, не обязательно должна быть квадратной. Например, психолог измерил три показателя интеллекта (вербальный, невербальный и общий) и школьные отметки по трем учебным предметам (литература, математика, физика) у 100 испытуемых - учащихся девятых классов. Исходная матрица данных будет иметь размер 100 × 6, а матрица интеркорреляций размер 6 × 6, поскольку в ней имеется только 6 переменных. При таком количестве переменных матрица интеркорреляций будет включать 15 коэффициентов и проанализировать ее не составит труда.
Однако представим, что произойдет, если психолог получит не 6, а 100 показателей от каждого испытуемого. В этом случае он должен будет анализировать 4950 коэффициентов корреляции. Число коэффициентов в матрице вычисляется по формуле n (n+1)/2 и в нашем случае равно соответственно (100×99)/2= 4950.
Очевидно, что провести визуальный анализ такой матрицы - задача труднореализуемая. Вместо этого психолог может выполнить математическую процедуру факторного анализа корреляционной матрицы размером 100 × 100 (100 испытуемых и 100 переменных) и таким путем получить более простой материал для интерпретации экспериментальных результатов.
Главное понятие факторного анализа - фактор. Это искусственный статистический показатель, возникающий в результате специальных преобразований таблицы коэффициентов корреляции между изучаемыми психологическими признаками, или матрицы интеркорреляций. Процедура извлечения факторов из матрицы интеркорреляций называется факторизацией матрицы. В результате факторизации из корреляционной матрицы может быть извлечено разное количество факторов вплоть до числа, равного количеству исходных переменных. Однако факторы, выделяемые в результате факторизации, как правило, неравноценны по своему значению.
Элементы факторной матрицы называются или весами»; и они представляют собой коэффициенты корреляции данного фактора со всеми показателями, использованными в исследовании. Факторная матрица очень важна, поскольку она показывает, как изучаемые показатели связаны с каждым выделенным фактором. При этом факторный вес демонстрирует меру, или тесноту, этой связи.
Поскольку каждый столбец факторной матрицы (фактор) является своего рода переменной величиной, то сами факторы также могут коррелировать между собой. Здесь возможны два случая: корреляция между факторами равна нулю, в таком случае факторы являются независимыми (ортогональными). Если корреляция между факторами больше нуля, то в таком случае факторы считаются зависимыми (облическими). Подчеркнем, что ортогональные факторы в отличие от облических дают более простые варианты взаимодействий внутри факторной матрицы.
В качестве иллюстрации ортогональных факторов часто приводят задачу Л. Терстоуна, который, взяв ряд коробок разных размеров и формы, измерил в каждой из них больше 20 различных показателей и вычислил корреляции между ними. Профакторизовав полученную матрицу интеркорреляций, он получил три фактора, корреляция между которыми была равна нулю. Этими факторами были «длина», «ширина» и «высота».
Для того чтобы лучше уловить сущность факторного анализа, разберем более подробно следующий пример.
Предположим, что психолог у случайной выборки студентов получает следующие данные:
V 1 - вес тела (в кг);
V 2 - количество посещений лекций и семинарских занятий по предмету;
V 3 - длина ноги (в см);
V 4 - количество прочитанных книг по предмету;
V 5 - длина руки (в см);
V 6 - экзаменационная оценка по предмету (V - от английского слова variable - переменная).
При анализе этих признаков не лишено оснований предположение о том, что переменные V 1 , К 3 и V 5 - будут связаны между собой, поскольку, чем больше человек, тем больше он весит и тем длиннее его конечности. Сказанное означает, что между этими переменными должны получиться статистически значимые коэффициенты корреляции, поскольку эти три переменные измеряют некоторое фундаментальное свойство индивидуумов в выборке, а именно: их размеры. Точно так же вероятно, что при вычислении корреляций между V 2 , V 4 и V 6 тоже будут получены достаточно высокие коэффициенты корреляции, поскольку посещение лекций и самостоятельные занятия будут способствовать получению более высоких оценок по изучаемому предмету.
Таким образом, из всего возможного массива коэффициентов, который получается путем перебора пар коррелируемых признаков V 1 и V 2 , V t и V 3 и т.д., предположительно выделятся два блока статистически значимых корреляций. Остальная часть корреляций - между признаками, входящими в разные блоки, вряд ли будет иметь статистически значимые коэффициенты, поскольку связи между такими признаками, как размер конечности и успеваемость по предмету, имеют, скорее всего, случайный характер. Итак, содержательный анализ 6 наших переменных показывает, что они, по сути дела, измеряют только две обобщенные характеристики, а именно: размеры тела и степень подготовленности по предмету.
К полученной матрице интеркорреляций, т.е. вычисленным попарно коэффициентам корреляций между всеми шестью переменными V 1 - V 6 , допустимо применить факторный анализ. Его можно проводить и вручную, с помощью калькулятора, однако процедура подобной статистической обработки очень трудоемка. По этой причине в настоящее время факторный анализ проводится на компьютерах, как правило, с помощью стандартных статистических пакетов. Во всех современных статистических пакетах есть программы для корреляционного и факторного анализов. Компьютерная программа по факторному анализу по существу пытается «объяснить» корреляции между переменными в терминах небольшого числа факторов (в нашем примере двух).
Предположим, что, используя компьютерную программу, мы получили матрицу интеркорреляций всех шести переменных и подвергли ее факторному анализу. В результате факторного анализа получилась таблица 13.1, которую называют «факторной матрицей», или «факторной структурной матрицей».
Таблица 13.1
| Переменная | Фактор 1 | Фактор 2 |
| V 1 | 0,91 | 0,01 |
| V 2 | 0,20 | 0,96 |
| V 3 | 0,94 | -0,15 |
| V 4 | 0,11 | 0,85 |
| V 5 | 0,89 | 0,07 |
| V 6 | -0,13 | 0,93 |
По традиции факторы представляются в таблице в виде столбцов, а переменные в виде строк. Заголовки столбцов таблицы 13.1 соответствуют номерам выделенных факторов, но более точно было бы их называть «факторные нагрузки», или «веса», по фактору 1, то же самое по фактору 2. Как указывалось выше, факторные нагрузки, или веса, представляют собой корреляции между соответствующей переменной и данным фактором. Например, первое число 0,91 в первом факторе означает, что корреляция между первым фактором и переменной V 1 равна 0,91. Чем выше факторная нагрузка по абсолютной величине, тем больше ее связь с фактором.
Из таблицы 13.1 видно, что переменные V 1 V 3 и V 5 имеют большие корреляции с фактором 1 (фактически переменная 3 имеет корреляцию близкую к 1 с фактором 1). В то же время переменные V 2 , V 3 и У 5 имеют корреляции близкие к 0 с фактором 2. Подобно этому фактор 2 высоко коррелирует с переменными V 2 , V 4 и V 6 и фактически не коррелирует с переменными V 1 , V 3 и V 5
В данном примере, очевидно, что существуют две структуры корреляций, и, следовательно, вся информация таблицы 13.1 определяется двумя факторами. Теперь начинается заключительный этап работы - интерпретация полученных данных. Анализируя факторную матрицу, очень важно учитывать знаки факторных нагрузок в каждом факторе. Если в одном и том же факторе встречаются нагрузки с противоположными знаками, это означает, что между переменными, имеющими противоположные знаки, существует обратно пропорциональная зависимость.
Отметим, что при интерпретации фактора для удобства можно изменить знаки всех нагрузок по данному фактору на противоположные.
Факторная матрица показывает также, какие переменные образуют каждый фактор. Это связано, прежде всего, с уровнем значимости факторного веса. По традиции минимальный уровень значимости коэффициентов корреляции в факторном анализе берется равным 0,4 или даже 0,3 (по абсолютной величине), поскольку нет специальных таблиц, по которым можно было бы определить критические значения для уровня значимости в факторной матрице. Следовательно, самый простой способ увидеть какие переменные «принадлежат» фактору – это значит отметить те из них, которые имеют нагрузки выше, чем 0,4 (или меньше чем - 0,4). Укажем, что в компьютерных пакетах иногда уровень значимости факторного веса определяется самой программой и устанавливается на более высоком уровне, например 0,7.
Так, из таблицы 13.1, следует вывод, что фактор 1 - это сочетание переменных V 1 К 3 и V 5 (но не V 1 , K 4 и V 6 , поскольку их факторные нагрузки по модулю меньше чем 0,4). Подобно этому фактор 2 представляет собой сочетание переменных V 2 , V 4 и V 6 .
Выделенный в результате факторизации фактор представляет собой совокупность тех переменных из числа включенных в анализ, которые имеют значимые нагрузки. Нередко случается, однако, что в фактор входит только одна переменная со значимым факторным весом, а остальные имеют незначимую факторную нагрузку. В этом случае фактор будет определяться по названию единственной значимой переменной.
В сущности, фактор можно рассматривать как искусственную «единицу» группировки переменных (признаков) на основе имеющихся между ними связей. Эта единица является условной, потому что, изменив определенные условия процедуры факторизации матрицы интеркорреляций, можно получить иную факторную матрицу (структуру). В новой матрице может оказаться иным распределение переменных по факторам и их факторные нагрузки.
В связи с этим в факторном анализе существует понятие «простая структура». Простой называют структуру факторной матрицы, в которой каждая переменная имеет значимые нагрузки только по одному из факторов, а сами факторы ортогональны, т.е. не зависят друг от друга. В нашем примере два общих фактора независимы. Факторная матрица с простой структурой позволяет провести интерпретацию полученного результата и дать наименование каждому фактору. В нашем случае фактор первый - «размеры тела», фактор второй - «уровень подготовленности».
Сказанное выше не исчерпывает содержательных возможностей факторной матрицы. Из нее можно извлечь дополнительные характеристики, позволяющие более детально исследовать связи переменных и факторов. Эти характеристики называются «общность» и «собственное значение» фактора.
Однако, прежде чем представить их описание, укажем на одно принципиально важное свойство коэффициента корреляции, благодаря которому получают эти характеристики. Коэффициент корреляции, возведенный в квадрат (т.е. помноженный сам на себя), показывает, какая часть дисперсии (вариативности) признака является общей для двух переменных, или, говоря проще, насколько сильно эти переменные перекрываются. Так, например, две переменные с корреляцией 0,9 перекрываются со степенью 0,9 х 0,9 = 0,81. Это означает, что 81% дисперсии той и другой переменной являются общими, т.е. совпадают. Напомним, что факторные нагрузки в факторной матрице - это коэффициенты корреляции между факторами и переменными, поэтому, возведенная в квадрат факторная нагрузка характеризует степень общности (или перекрытия) дисперсий данной переменной и данного фактором.
Если полученные факторы не зависят друг от друга («ортогональное» решение), по весам факторной матрицы можно определить, какая часть дисперсии является общей для переменной и фактора. Вычислить, какая часть вариативности каждой переменной совпадает с вариативностью факторов, можно простым суммированием квадратов факторных нагрузок по всем факторам. Из таблицы 13.1, например, следует, что 0,91 × 0,91 + + 0,01 × 0,01 = 0,8282, т.е. около 82% вариативности первой переменной «объясняется» двумя первыми факторами. Полученная величина называется общностью переменной, в данном случае переменной V 1
Переменные могут иметь разную степень общности с факторами. Переменная с большей общностью имеет значительную степень перекрытия (большую долю дисперсии) с одним или несколькими факторами. Низкая общность подразумевает, что все корреляции между переменными и факторами невелики. Это означает, что ни один из факторов не имеет совпадающей доли вариативности с данной переменной. Низкая общность может свидетельствовать о том, что переменная измеряет нечто качественно отличающееся от других переменных, включенных в анализ. Например, одна переменная, связанная с оценкой мотивации среди заданий, оценивающих способности, будет иметь общность с факторами способностей близкую к нулю.
Малая общность может также означать, что определенное задание испытывает на себе сильное влияние ошибки измерения или крайне сложно для испытуемого. Возможно, напротив, также, что задание настолько просто, что каждый испытуемый дает на него правильный ответ, или задание настолько нечетко по содержанию, что испытуемый не понимает суть вопроса. Таким образом, низкая общность подразумевает, что данная переменная не совмещается с факторами по одной из причин: либо переменная измеряет другое понятие, либо переменная имеет большую ошибку измерения, либо существуют искажающие дисперсию признака различия между испытуемыми в вариантах ответа на это задание.
Наконец, с помощью такой характеристики, как собственное значение фактора, можно определить относительную значимость каждого из выделенных факторов. Для этого надо вычислить, какую часть дисперсии (вариативности) объясняет каждый фактор. Тот фактор, который объясняет 45% дисперсии (перекрытия) между переменными в исходной корреляционной матрице, очевидно, является более значимым, чем другой, который объясняет только 25% дисперсии. Эти рассуждения, однако, допустимы, если факторы ортогональны, иначе говоря, не зависят друг от друга.
Для того чтобы вычислить собственное значение фактора, нужно возвести в квадрат факторные нагрузки, и сложить их по столбцу. Используя данные таблицы 13.1 можно убедиться, что собственное значение фактора 1 составляет (0,91 × 0,91 + 0,20 × 0,20 + 0,94 × 0,94 + 0,11 × 0,11 + 0,84 × 0,84 + (- 0,13) ×
× (-0,13)) = 2,4863. Если собственное значение фактора разделить на число переменных (6 в нашем примере), то полученное число покажет, какая доля дисперсии объясняется данным фактором. В нашем случае получится 2,4863∙100%/6 = 41,4%. Иными словами, фактор 1 объясняет около 41% информации (дисперсии) в исходной корреляционной матрице. Аналогичный подсчет для второго фактора даст 41,5%. В сумме это будет составлять 82,9%.
Таким образом, два общих фактора, будучи объединены, объясняют только 82,9% дисперсии показателей исходной корреляционной матрицы. Что случилось с «оставшимися» 17,1%? Дело в том, что, рассматривая корреляции между 6 переменными, мы отмечали, что корреляции распадаются на два отдельных блока, и поэтому решили, что логично анализировать материал в понятиях двух факторов, а не 6, как и количество исходных переменных. Другими словами, число конструктов, необходимых, чтобы описать данные, уменьшилось с 6 (число переменных) до 2 (число общих факторов). В результате факторизации часть информации в исходной корреляционной матрице была принесена в жертву построению двухфакторной модели. Единственным условием, при котором информация не утрачивается, было бы рассмотрение шестифакторной модели.
После того как уравнение регрессии построено и с помощью коэффициента детерминации оценена его точность, остается открытым вопрос за счет чего достигнута эта точность и соответственно можно ли этому уравнению доверять. Дело в том, что уравнение регрессии строилось не по генеральной совокупности, которая неизвестна, а по выборке из нее. Точки из генеральной совокупности попадают в выборку случайным образом, по этому в соответствии с теорией вероятности среди прочих случаев возможен вариант, когда выборка из “широкой” генеральной совокупности окажется “узкой” (рис. 15).
Рис. 15. Возможный вариант попадания точек в выборку из генеральной совокупности.
В этом случае:
а) уравнение регрессии, построенное по выборке, может значительно отличаться от уравнения регрессии для генеральной совокупности, что приведет к ошибкам прогноза;
б) коэффициент детерминации и другие характеристики точности окажутся неоправданно высокими и будут вводить в заблуждение о прогнозных качествах уравнения.
В предельном случае не исключен вариант, когда из генеральной совокупности представляющей собой облако с главной осью параллельной горизонтальной оси (отсутствует связь между переменными) за счет случайного отбора будет получена выборка, главная ось которой окажется наклоненной к оси. Таким образом, попытки прогнозировать очередные значения генеральной совокупности опираясь на данные выборки из нее чреваты не только ошибками в оценке силы и направления связи между зависимой и независимой переменными, но и опасностью найти связь между переменными там, где на самом деле ее нет.
В условиях отсутствия информации обо всех точках генеральной совокупности единственный способ уменьшить ошибки в первом случае заключается в использовании при оценке коэффициентов уравнения регрессии метода, обеспечивающего их несмещенность и эффективность. А вероятность наступления второго случая может быть значительно снижена благодаря тому, что априори известно одно свойство генеральной совокупности с двумя независимыми друг от друга переменными – в ней отсутствует именно эта связь. Достигается это снижение за счет проверки статистической значимости полученного уравнения регрессии.
Один из наиболее часто используемых вариантов проверки заключается в следующем. Для полученного уравнения регрессии определяется -статистика - характеристика точности уравнения регрессии, представляющая собой отношение той части дисперсии зависимой переменной которая объяснена уравнением регрессии к необъясненной (остаточной) части дисперсии. Уравнение для определения -статистики в случае многомерной регрессии имеет вид:

где: - объясненная дисперсия - часть дисперсии зависимой переменной Y которая объяснена уравнением регрессии;
Остаточная дисперсия - часть дисперсии зависимой переменной Y которая не объяснена уравнением регрессии, ее наличие является следствием действия случайной составляющей;
Число точек в выборке;
Число переменных в уравнении регрессии.
Как видно из приведенной формулы, дисперсии определяются как частное от деления соответствующей суммы квадратов на число степеней свободы. Число степеней свободы это минимально необходимое число значений зависимой переменной, которых достаточно для получения искомой характеристики выборки и которые могут свободно варьироваться с учетом того, что для этой выборки известны все другие величины, используемые для расчета искомой характеристики.
Для получения остаточной дисперсии необходимы коэффициенты уравнения регрессии. В случае парной линейной регрессии коэффициентов два, по этому в соответствии с формулой (принимая ) число степеней свободы равно . Имеется в виду, что для определения остаточной дисперсии достаточно знать коэффициенты уравнения регрессии и только значений зависимой переменной из выборки. Оставшиеся два значения могут быть вычислены на основании этих данных, а значит, не являются свободно варьируемыми.
Для вычисления объясненной дисперсии значений зависимой переменной вообще не требуются, так как ее можно вычислить, зная коэффициенты регрессии при независимых переменных и дисперсию независимой переменной. Для того чтобы убедиться в этом, достаточно вспомнить приводившееся ранее выражение ![]() . По этому число степеней свободы для остаточной дисперсии равно числу независимых переменных в уравнении регрессии (для парной линейной регрессии ).
. По этому число степеней свободы для остаточной дисперсии равно числу независимых переменных в уравнении регрессии (для парной линейной регрессии ).
В результате -критерий для уравнения парной линейной регрессии определяется по формуле:
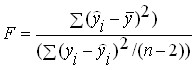 .
.
В теории вероятности доказано, что -критерий уравнения регрессии, полученного для выборки из генеральной совокупности у которой отсутствует связь между зависимой и независимой переменной имеет распределение Фишера, достаточно хорошо изученное. Благодаря этому для любого значения -критерия можно рассчитать вероятность его появления и наоборот, определить то значение -критерия которое он не сможет превысить с заданной вероятностью.
Для осуществления статистической проверки значимости уравнения регрессии формулируется нулевая гипотеза об отсутствии связи между переменными (все коэффициенты при переменных равны нулю) и выбирается уровень значимости .
Уровень значимости – это допустимая вероятность совершить ошибку первого рода – отвергнуть в результате проверки верную нулевую гипотезу. В рассматриваемом случае совершить ошибку первого рода означает признать по выборке наличие связи между переменными в генеральной совокупности, когда на самом деле ее там нет.
Обычно уровень значимости принимается равным 5% или 1%. Чем выше уровень значимости (чем меньше ), тем выше уровень надежности теста, равный , т.е. тем больше шанс избежать ошибки признания по выборке наличия связи у генеральной совокупности на самом деле несвязанных между собой переменных. Но с ростом уровня значимости возрастает опасность совершения ошибки второго рода – отвергнуть верную нулевую гипотезу, т.е. не заметить по выборке имеющуюся на самом деле связь переменных в генеральной совокупности. По этому, в зависимости от того, какая ошибка имеет большие негативные последствия, выбирают тот или иной уровень значимости.
Для выбранного уровня значимости по распределению Фишера определяется табличное значение вероятность превышения, которого в выборке мощностью , полученной из генеральной совокупности без связи между переменными, не превышает уровня значимости. сравнивается с фактическим значением критерия для регрессионного уравнения .
Если выполняется условие , то ошибочное обнаружение связи со значением -критерия равным или большим по выборке из генеральной совокупности с несвязанными между собой переменными будет происходить с вероятностью меньшей чем уровень значимости. В соответствии с правилом “очень редких событий не бывает”, приходим к выводу, что установленная по выборке связь между переменными имеется и в генеральной совокупности, из которой она получена.
Если же оказывается , то уравнение регрессии статистически не значимо. Иными словами существует реальная вероятность того, что по выборке установлена не существующая в реальности связь между переменными. К уравнению, не выдержавшему проверку на статистическую значимость, относятся так же, как и к лекарству с истекшим сроком годнос-
Ти – такие лекарства не обязательно испорчены, но раз нет уверенности в их качестве, то их предпочитают не использовать. Это правило не уберегает от всех ошибок, но позволяет избежать наиболее грубых, что тоже достаточно важно.
Второй вариант проверки, более удобный в случае использования электронных таблиц, это сопоставление вероятности появления полученного значения -критерия с уровнем значимости. Если эта вероятность оказывается ниже уровня значимости , значит уравнение статистически значимо, в противном случае нет.
После того как выполнена проверка статистической значимости регрессионного уравнения в целом полезно, особенно для многомерных зависимостей осуществить проверку на статистическую значимость полученных коэффициентов регрессии. Идеология проверки такая же как и при проверке уравнения в целом но в качестве критерия используется -критерий Стьюдента, определяемый по формулам:
 и
и 
где: , - значения критерия Стьюдента для коэффициентов и соответственно;
 - остаточная дисперсия уравнения регрессии;
- остаточная дисперсия уравнения регрессии;
Число точек в выборке;
Число переменных в выборке, для парной линейной регрессии .
Полученные фактические значения критерия Стьюдента сравниваются с табличными значениями ![]() , полученными из распределения Стьюдента. Если оказывается, что , то соответствующий коэффициент статистически значим, в противном случае нет. Второй вариант проверки статистической значимости коэффициентов – определить вероятность появления критерия Стьюдента и сравнить с уровнем значимости .
, полученными из распределения Стьюдента. Если оказывается, что , то соответствующий коэффициент статистически значим, в противном случае нет. Второй вариант проверки статистической значимости коэффициентов – определить вероятность появления критерия Стьюдента и сравнить с уровнем значимости .
Для переменных, чьи коэффициенты оказались статистически не значимы, велика вероятность того, что их влияние на зависимую переменную в генеральной совокупности вообще отсутствует. По этому или необходимо увеличить число точек в выборке, тогда возможно коэффициент станет статистически значимым и заодно уточнится его значение, или в качестве независимых переменных найти другие, более тесно связанные с зависимой переменной. Точность прогнозирования при этом в обоих случаях возрастет.
В качестве экспрессного метода оценки значимости коэффициентов уравнения регрессии можно применять следующее правило – если критерий Стьюдента больше 3, то такой коэффициент, как правило, оказывается статистически значим. А вообще считается, что для получения статистически значимых уравнений регрессии необходимо, чтобы выполнялось условие .
Стандартная ошибка прогнозирования по полученному уравнению регрессии неизвестного значения при известном оценивают по формуле:

Таким образом прогноз с доверительной вероятностью 68% может быть представлен в виде:
В случае если требуется иная доверительная вероятность , то для уровня значимости необходимо найти критерий Стьюдента и доверительный интервал для прогноза с уровнем надежности будет равен ![]() .
.
Прогнозирование многомерных и нелинейных зависимостей
В случае если прогнозируемая величина зависит от нескольких независимых переменных, то в этом случае имеется многомерная регрессия вида:
где: - коэффициенты регрессии, описывающие влияние переменных на прогнозируемую величину.
Методика определения коэффициентов регрессии не отличается от парной линейной регрессии, особенно при использовании электронной таблицы, так как там применяется одна и та же функция и для парной и для многомерной линейной регрессии. При этом желательно чтобы между независимыми переменными отсутствовали взаимосвязи, т.е. изменение одной переменной не сказывалось на значениях других переменных. Но это требование не является обязательным, важно чтобы между переменными отсутствовали функциональные линейные зависимости. Описанные выше процедуры проверки статистической значимости полученного уравнения регрессии и его отдельных коэффициентов, оценка точности прогнозирования остается такой же как и для случая парной линейной регрессии. В тоже время применение многомерных регрессий вместо парной обычно позволяет при надлежащем выборе переменных существенно повысить точность описания поведения зависимой переменной, а значит и точность прогнозирования.
Кроме этого уравнения многомерной линейной регрессии позволяют описать и нелинейную зависимость прогнозируемой величины от независимых переменных. Процедура приведения нелинейного уравнения к линейному виду называется линеаризацией. В частности если эта зависимость описывается полиномом степени отличной от 1, то, осуществив замену переменных со степенями отличными от единицы на новые переменные в первой степени, получаем задачу многомерной линейной регрессии вместо нелинейной. Так, например если влияние независимой переменной описывается параболой вида
![]()
то замена позволяет преобразовать нелинейную задачу к многомерной линейной вида
![]()
Так же легко могут быть преобразованы нелинейные задачи у которых нелинейность возникает вследствие того, что прогнозируемая величина зависит от произведения независимых переменных. Для учета такого влияния необходимо ввести новую переменную равную этому произведению.
В тех случаях, когда нелинейность описывается более сложными зависимостями, линеаризация возможна за счет преобразования координат. Для этого рассчитываются значения ![]() и строятся графики зависимости исходных точек в различных комбинациях преобразованных переменных. Та комбинация преобразованных координат или преобразованных и не преобразованных координат, в которой зависимость ближе всего к прямой линии подсказывает замену переменных которая приведет к преобразованию нелинейной зависимости к линейному виду. Например, нелинейная зависимость вида
и строятся графики зависимости исходных точек в различных комбинациях преобразованных переменных. Та комбинация преобразованных координат или преобразованных и не преобразованных координат, в которой зависимость ближе всего к прямой линии подсказывает замену переменных которая приведет к преобразованию нелинейной зависимости к линейному виду. Например, нелинейная зависимость вида
превращается в линейную вида
Полученные коэффициенты регрессии для преобразованного уравнения остаются несмещенными и эффективными, но проверка статистической значимости уравнения и коэффициентов невозможна
Проверка обоснованности применения метода наименьших квадратов
Применение метода наименьших квадратов обеспечивает эффективность и несмещенность оценок коэффициентов уравнения регрессии при соблюдении следующих условий (условий Гауса-Маркова):
3. значения не зависят друг от друга
4. значения не зависят от независимых переменных
Наиболее просто можно проверить соблюдение этих условий путем построения графиков остатков в зависимости от , затем от независимой (независимых) переменных. Если точки на этих графиках расположены в коридоре расположенном симметрично оси абсцисс и в расположении точек не просматриваются закономерности, то условия Гауса-Маркова выполнены и возможности повысить точность уравнения регрессии отсутствуют. Если это не так, то существует возможность существенно повысить точность уравнения и для этого необходимо обратиться к специальной литературе.
Регрессионный анализ — это статистический метод исследования, позволяющий показать зависимость того или иного параметра от одной либо нескольких независимых переменных. В докомпьютерную эру его применение было достаточно затруднительно, особенно если речь шла о больших объемах данных. Сегодня, узнав как построить регрессию в Excel, можно решать сложные статистические задачи буквально за пару минут. Ниже представлены конкретные примеры из области экономики.
Виды регрессии
Само это понятие было введено в математику в 1886 году. Регрессия бывает:
- линейной;
- параболической;
- степенной;
- экспоненциальной;
- гиперболической;
- показательной;
- логарифмической.
Пример 1
Рассмотрим задачу определения зависимости количества уволившихся членов коллектива от средней зарплаты на 6 промышленных предприятиях.
Задача. На шести предприятиях проанализировали среднемесячную заработную плату и количество сотрудников, которые уволились по собственному желанию. В табличной форме имеем:
Количество уволившихся | Зарплата |
||
30000 рублей |
|||
35000 рублей |
|||
40000 рублей |
|||
45000 рублей |
|||
50000 рублей |
|||
55000 рублей |
|||
60000 рублей |
Для задачи определения зависимости количества уволившихся работников от средней зарплаты на 6 предприятиях модель регрессии имеет вид уравнения Y = а 0 + а 1 x 1 +…+а k x k , где х i — влияющие переменные, a i — коэффициенты регрессии, a k — число факторов.
Для данной задачи Y — это показатель уволившихся сотрудников, а влияющий фактор — зарплата, которую обозначаем X.
Использование возможностей табличного процессора «Эксель»
Анализу регрессии в Excel должно предшествовать применение к имеющимся табличным данным встроенных функций. Однако для этих целей лучше воспользоваться очень полезной надстройкой «Пакет анализа». Для его активации нужно:
- с вкладки «Файл» перейти в раздел «Параметры»;
- в открывшемся окне выбрать строку «Надстройки»;
- щелкнуть по кнопке «Перейти», расположенной внизу, справа от строки «Управление»;
- поставить галочку рядом с названием «Пакет анализа» и подтвердить свои действия, нажав «Ок».
Если все сделано правильно, в правой части вкладки «Данные», расположенном над рабочим листом «Эксель», появится нужная кнопка.
в Excel
Теперь, когда под рукой есть все необходимые виртуальные инструменты для осуществления эконометрических расчетов, можем приступить к решению нашей задачи. Для этого:
- щелкаем по кнопке «Анализ данных»;
- в открывшемся окне нажимаем на кнопку «Регрессия»;
- в появившуюся вкладку вводим диапазон значений для Y (количество уволившихся работников) и для X (их зарплаты);
- подтверждаем свои действия нажатием кнопки «Ok».
В результате программа автоматически заполнит новый лист табличного процессора данными анализа регрессии. Обратите внимание! В Excel есть возможность самостоятельно задать место, которое вы предпочитаете для этой цели. Например, это может быть тот же лист, где находятся значения Y и X, или даже новая книга, специально предназначенная для хранения подобных данных.
Анализ результатов регрессии для R-квадрата
В Excel данные полученные в ходе обработки данных рассматриваемого примера имеют вид:
Прежде всего, следует обратить внимание на значение R-квадрата. Он представляет собой коэффициент детерминации. В данном примере R-квадрат = 0,755 (75,5%), т. е. расчетные параметры модели объясняют зависимость между рассматриваемыми параметрами на 75,5 %. Чем выше значение коэффициента детерминации, тем выбранная модель считается более применимой для конкретной задачи. Считается, что она корректно описывает реальную ситуацию при значении R-квадрата выше 0,8. Если R-квадрата<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Анализ коэффициентов
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется.
Множественная регрессия
Под таким термином понимается уравнение связи с несколькими независимыми переменными вида:
y=f(x 1 +x 2 +…x m) + ε, где y — это результативный признак (зависимая переменная), а x 1 , x 2 , …x m — это признаки-факторы (независимые переменные).
Оценка параметров
Для множественной регрессии (МР) ее осуществляют, используя метод наименьших квадратов (МНК). Для линейных уравнений вида Y = a + b 1 x 1 +…+b m x m + ε строим систему нормальных уравнений (см. ниже)

Чтобы понять принцип метода, рассмотрим двухфакторный случай. Тогда имеем ситуацию, описываемую формулой

Отсюда получаем:

где σ — это дисперсия соответствующего признака, отраженного в индексе.
МНК применим к уравнению МР в стандартизируемом масштабе. В таком случае получаем уравнение:

в котором t y , t x 1, … t xm — стандартизируемые переменные, для которых средние значения равны 0; β i — стандартизированные коэффициенты регрессии, а среднеквадратическое отклонение — 1.
Обратите внимание, что все β i в данном случае заданы, как нормируемые и централизируемые, поэтому их сравнение между собой считается корректным и допустимым. Кроме того, принято осуществлять отсев факторов, отбрасывая те из них, у которых наименьшие значения βi.
Задача с использованием уравнения линейной регрессии
Предположим, имеется таблица динамики цены конкретного товара N в течение последних 8 месяцев. Необходимо принять решение о целесообразности приобретения его партии по цене 1850 руб./т.
номер месяца | название месяца | цена товара N |
|
1750 рублей за тонну |
|||
1755 рублей за тонну |
|||
1767 рублей за тонну |
|||
1760 рублей за тонну |
|||
1770 рублей за тонну |
|||
1790 рублей за тонну |
|||
1810 рублей за тонну |
|||
1840 рублей за тонну |
|||
Для решения этой задачи в табличном процессоре «Эксель» требуется задействовать уже известный по представленному выше примеру инструмент «Анализ данных». Далее выбирают раздел «Регрессия» и задают параметры. Нужно помнить, что в поле «Входной интервал Y» должен вводиться диапазон значений для зависимой переменной (в данном случае цены на товар в конкретные месяцы года), а в «Входной интервал X» — для независимой (номер месяца). Подтверждаем действия нажатием «Ok». На новом листе (если так было указано) получаем данные для регрессии.
Строим по ним линейное уравнение вида y=ax+b, где в качестве параметров a и b выступают коэффициенты строки с наименованием номера месяца и коэффициенты и строки «Y-пересечение» из листа с результатами регрессионного анализа. Таким образом, линейное уравнение регрессии (УР) для задачи 3 записывается в виде:
Цена на товар N = 11,714* номер месяца + 1727,54.
или в алгебраических обозначениях
y = 11,714 x + 1727,54
Анализ результатов
Чтобы решить, адекватно ли полученное уравнения линейной регрессии, используются коэффициенты множественной корреляции (КМК) и детерминации, а также критерий Фишера и критерий Стьюдента. В таблице «Эксель» с результатами регрессии они выступают под названиями множественный R, R-квадрат, F-статистика и t-статистика соответственно.
КМК R дает возможность оценить тесноту вероятностной связи между независимой и зависимой переменными. Ее высокое значение свидетельствует о достаточно сильной связи между переменными «Номер месяца» и «Цена товара N в рублях за 1 тонну». Однако, характер этой связи остается неизвестным.
Квадрат коэффициента детерминации R 2 (RI) представляет собой числовую характеристику доли общего разброса и показывает, разброс какой части экспериментальных данных, т.е. значений зависимой переменной соответствует уравнению линейной регрессии. В рассматриваемой задаче эта величина равна 84,8%, т. е. статистические данные с высокой степенью точности описываются полученным УР.
F-статистика, называемая также критерием Фишера, используется для оценки значимости линейной зависимости, опровергая или подтверждая гипотезу о ее существовании.
(критерий Стьюдента) помогает оценивать значимость коэффициента при неизвестной либо свободного члена линейной зависимости. Если значение t-критерия > t кр, то гипотеза о незначимости свободного члена линейного уравнения отвергается.
В рассматриваемой задаче для свободного члена посредством инструментов «Эксель» было получено, что t=169,20903, а p=2,89Е-12, т. е. имеем нулевую вероятность того, что будет отвергнута верная гипотеза о незначимости свободного члена. Для коэффициента при неизвестной t=5,79405, а p=0,001158. Иными словами вероятность того, что будет отвергнута верная гипотеза о незначимости коэффициента при неизвестной, равна 0,12%.
Таким образом, можно утверждать, что полученное уравнение линейной регрессии адекватно.
Задача о целесообразности покупки пакета акций
Множественная регрессия в Excel выполняется с использованием все того же инструмента «Анализ данных». Рассмотрим конкретную прикладную задачу.
Руководство компания «NNN» должно принять решение о целесообразности покупки 20 % пакета акций АО «MMM». Стоимость пакета (СП) составляет 70 млн американских долларов. Специалистами «NNN» собраны данные об аналогичных сделках. Было принято решение оценивать стоимость пакета акций по таким параметрам, выраженным в миллионах американских долларов, как:
- кредиторская задолженность (VK);
- объем годового оборота (VO);
- дебиторская задолженность (VD);
- стоимость основных фондов (СОФ).
Кроме того, используется параметр задолженность предприятия по зарплате (V3 П) в тысячах американских долларов.
Решение средствами табличного процессора Excel
Прежде всего, необходимо составить таблицу исходных данных. Она имеет следующий вид:

- вызывают окно «Анализ данных»;
- выбирают раздел «Регрессия»;
- в окошко «Входной интервал Y» вводят диапазон значений зависимых переменных из столбца G;
- щелкают по иконке с красной стрелкой справа от окна «Входной интервал X» и выделяют на листе диапазон всех значений из столбцов B,C, D, F.
Отмечают пункт «Новый рабочий лист» и нажимают «Ok».
Получают анализ регрессии для данной задачи.

Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Проверку значимости уравнения регрессии произведем на основе
F-критерия Фишера:
Значение F-критерия Фишера можно найти в таблице Дисперсионный анализ протокола Еxcel. Табличное значение F-критерия при доверительной вероятности α = 0,95 и числе степеней свободы, равном v1 = k = 2 и v2 = n – k – 1= 50 – 2 – 1 = 47, составляет 0,051.
Поскольку Fрасч > Fтабл, уравнение регрессии следует признать значимым, то есть его можно использовать для анализа и прогнозирования.
Оценку значимости коэффициентов полученной модели, используя результаты отчета Excel, можно осуществить тремя способами.
Коэффициент уравнения регрессии признается значимым в том случае, если:
1) наблюдаемое значение t-статистики Стьюдента для этого коэффициента больше, чем критическое (табличное) значение статистики Стьюдента (для заданного уровня значимости, например α = 0,05, и числа степеней свободы df = n – k – 1, где n – число наблюдений, а k – число факторов в модели);
2) Р-значение t-статистики Стьюдента для этого коэффициента меньше, чем уровень значимости, например, α = 0,05;
3) доверительный интервал для этого коэффициента, вычисленный с некоторой доверительной вероятностью (например, 95%), не содержит ноль внутри себя, то есть нижняя 95% и верхняя 95% границы доверительного интервала имеют одинаковые знаки.
Значимость коэффициентов a 1 и a 2 проверим по второму и третьему способам:
P-значение (a 1 ) = 0,00 < 0,01 < 0,05.
Р-значение (a 2 ) = 0,00 < 0,01 < 0,05.
Следовательно, коэффициенты a 1 и a 2 значимы при 1%-ном уровне, а тем более при 5%-ном уровне значимости. Нижние и верхние 95% границы доверительного интервала имеют одинаковые знаки, следовательно, коэффициенты a 1 и a 2 значимы.
Определение объясняющей переменной, от которой
Может зависеть дисперсия случайных возмущений.
Проверка выполнения условия гомоскедастичности
Остатков по тесту Гольдфельда–Квандта
При проверке предпосылки МНК о гомоскедастичности остатков в модели множественной регрессии следует вначале определить, по отношению к какому из факторов дисперсия остатков более всего нарушена. Это можно сделать в результате визуального исследования графиков остатков, построенных по каждому из факторов, включенных в модель. Та из объясняющих переменных, от которой больше зависит дисперсия случайных возмущений, и будет упорядочена по возрастанию фактических значений при проверке теста Гольдфельда–Квандта. Графики легко получить в отчете, который формируется в результате использования инструмента Регрессия в пакете Анализ данных).


Графики остатков по каждому из факторов двухфакторной модели
Из представленных графиков видно, что дисперсия остатков более всего нарушена по отношению к фактору Краткосрочная дебиторская задолженность.
Проверим наличие гомоскедастичности в остатках двухфакторной модели на основе теста Гольдфельда–Квандта.
Уберем из середины упорядоченной совокупности С = 1/4 · n = 1/4 · 50 = 12,5 (12) значения. В результате получим две совокупности соответственно с малыми и большими значениями Х4.
Для каждой совокупности выполним расчеты:
Упорядочим переменные Y и X2 по возрастанию фактора Х4 (в Excel для этого можно использовать команду Данные – Сортировка по возрастанию Х4):
|
Данные, отсортированные по возрастанию X4: |
||
|
Сумма |
111234876536,511 |
||||
|
966570797682,068 |
|||||
|
455748832843,413 |
|||||
|
232578961097,877 |
|||||
|
834043911651,192 |
|||||
|
193722998259,505 |
|||||
|
1246409153509,290 |
|||||
|
31419681912489,100 |
|||||
|
2172804245053,280 |
|||||
|
768665257272,099 |
|||||
|
2732445494273,330 |
|||||
|
163253156450,331 |
|||||
|
18379855056009,900 |
|||||
|
10336693841766,000 |
|||||
|
Сумма |
69977593738424,600 |
Уравнения для совокупностей
Y = -27275,746 + 0,126X2 + 1,817 X4
Y = 61439,511 + 0,228X2 + 0,140X4
Результаты данной таблицы получены с помощью инструмента Регрессия поочередно к каждой из полученных совокупностей.
4. Найдем отношение полученных остаточных сумм квадратов
(в числителе должна быть большая сумма):
5. Вывод о наличии гомоскедастичности остатков делаем с помощью F-критерия Фишера с уровнем значимости α = 0,05 и двумя одинаковыми степенями свободы k1 = k2 = == 17
где р – число параметров уравнения регрессии:
Fтабл (0,05; 17; 17) = 9,28.
Так как Fтабл > R ,то подтверждается гомоскедастичность в остатках двухфакторной регрессии.









- Сонник: книги, книги на полках, старые книги, писать книгу
- К чему снится ива по соннику
- Биография, интересные факты
- К железам какой секреции относится поджелудочная железа
- Где находится кашмир. Кашмир — другая Индия. Территориальная структура Кашмира
- Родился александр александрович алябьев Сообщение о алябьев александр александрович
- Шпаргалка: Образование древнерусского государства
- Формирование древнерусского государства
- Заговоры от врагов и недоброжелателей Магия заставить замолчать завязать язык
- алоэ – амулет от всех бед на подоконнике
- Заговоры на красоту и привлекательность Заговор для красоты на мед и алой
- Национальный транс: Культура и магия гаитянского вуду Гаитянский культ 4 буквы сканворд
- Каша из топора кратко. Сказка Каша из топора. Русская народная сказка. Хитрая наука — русская народная сказка
- Яблоко от яблони недалеко падает
- Михаил Зощенко. Самое главное. Самое главное, зощенко для детей Михаил зощенко самое главное
- Великая дивеевская тайна
- Последняя тайна царицы тамары Грузинская царица тамара
- Владыка петр. Петр Воронежский, сщмч. «Что это вы так трудитесь, владыко святый?»
- Апостол иуда искариот - святые - история - каталог статей - любовь безусловная Критика неканонического восприятия Иуды Искариота
- Когнитивно-поведенческая психотерапия Бек когнитивная терапия и эмоциональные расстройства